

Three months ago, I sat in the back office of a commercial property inspection company watching their operations manager manually merge seven different spreadsheets from field teams across four states. Each sheet had different column headers. Different naming conventions. Different quality metrics. The company had grown from 12 inspectors to 47 in eighteen months, and their original "everyone knows what to do" system had completely collapsed.
This wasn't a technology problem. It was an architecture problem.
Most inspection programs start the same way. A handful of experienced inspectors, clear communication, simple reporting. Everyone understands the standards because everyone helped create them. Quality stays high because the founder reviews every report. Then growth happens. New markets open. More inspectors join. Suddenly that tight feedback loop becomes a game of telephone across multiple sites, and quality becomes whatever each site manager thinks it should be.
The companies that successfully build scalable inspection programs don't just add more inspectors and hope for the best. They build operational architecture that maintains consistency whether they're running 5 inspections a day or 500.
The inspection scaling paradox
Scaling inspection programs hits breaking points where the entire system needs restructuring. You can't slowly transition from founder-reviewed reports to distributed quality control. These transitions happen suddenly, usually after something goes wrong.
A residential inspection company discovered this when they'd grown from 8 to 23 inspectors over two years, still using their original quality process: the operations manager spot-checked 20% of reports. Worked great at 8 inspectors. At 23 inspectors across three regions, that same manager was drowning in 80+ reports weekly while critical issues slipped through in the unchecked 80%.
The real challenge isn't volume—it's variance. Every new site develops its own interpretation of standards. Every new inspector brings their own habits. Without clear architecture, you end up with as many inspection programs as you have locations.
Consider what happens in a typical multi-site inspection operation without proper structure:
The main site runs inspections one way. They've refined their process over years. Inspectors know exactly what documentation to capture, which issues require immediate escalation, how to format reports. New sites copy what they think the process is, but miss crucial details. Site B starts combining two inspection types to save time. Site C begins using different severity classifications because "it makes more sense for our market." Site D hires an experienced inspector from a competitor who convinces them to adopt a completely different reporting format.
Six months later, you can't compare data across sites. Quality metrics mean different things in different locations. Training materials contradict each other. Clients receive wildly different experiences depending on which team handles their inspection.
Role clarity at scale: beyond job descriptions
Most inspection companies write job descriptions and think they've defined roles. But role definition for scalable operations goes much deeper than listing responsibilities. It requires mapping decision authority, escalation paths, and overlap zones where roles intersect.
Eliminate inspection delays and errors.
Chekzly helps you plan, execute, and document inspections efficiently and accurately.
- Real-time inspection tracking
- Automated report generation
- Compliance and checklist management
No credit card required
Take the seemingly simple role of "Lead Inspector." In a 5-person team, everyone knows what this means. In a 50-person operation across multiple sites, you need explicit clarity on decision boundaries, information flow, and quality authority.
Can a Lead Inspector modify inspection sequences? Approve overtime? Override software flags? Change report formats? Stop an inspection mid-process? Each decision needs a clear yes/no, not "use your judgment."
Who does the Lead Inspector update, when, and through what channel? Daily summaries? Exception-only reporting? Real-time issue escalation? Without this clarity, you get either information bottlenecks or communication chaos.
Can they reject another inspector's work? Require re-inspection? Modify quality scores? Override client requests that compromise standards? These aren't theoretical questions—they come up weekly in growing operations.
A commercial inspection firm learned this after expanding to a second state. Their original Lead Inspector had developed the entire quality program, so his authority was absolute but informal. The new site's Lead Inspector, following the written job description, had no idea he was supposed to be reviewing every report before client delivery. Three months of uninspected reports went directly to clients before anyone noticed the gap.
The solution isn't more detailed job descriptions. It's creating what I call "role architecture"—a system that defines not just what each role does, but how roles interact as volume scales.
Effective role architecture in practice:
| Role Layer | Primary Function | Decision Authority | Quality Gates | Escalation Triggers |
|---|---|---|---|---|
| Field Inspector | Execute inspections | None beyond safety stops | Self-review checklist | Safety, access, scope issues |
| Senior Inspector | Complex inspections + field training | Modify inspection sequence, approve trainee work | Peer review on complex jobs | Technical disputes, client conflicts |
| Lead Inspector | Site quality + scheduling | Override software, approve exceptions, modify local processes | Reviews 20% random + all flagged | Systemic issues, multi-site problems |
| Regional Manager | Multi-site coordination | Change standards, approve new methods | Monthly pattern analysis | Standards conflicts, major client issues |
This isn't about creating bureaucracy. It's about preventing the confusion that kills quality when you're running hundreds of inspections across multiple locations.
Building your inspection data model
The companies that successfully scale inspection programs treat data architecture as seriously as they treat inspector training. Not because they love spreadsheets, but because inconsistent data structures make it impossible to maintain quality across sites.
Your inspection data model needs three layers. First, the core data structure—unchangeable fields that every inspection must capture. Property ID, inspection type, inspector ID, start/end times, result codes. Sounds basic until you realize Site A uses "PASS/FAIL" while Site B uses "1/2/3/4/5" and Site C writes paragraphs.
Second, flexible capture layer—fields that vary by inspection type or market but follow consistent naming and format rules. A roof inspection needs different data than an electrical inspection, but both should structure findings the same way.
Third, analysis layer—calculated fields and rollups that enable cross-site comparison. Average inspection time, defect rates, re-inspection frequency, client satisfaction scores. Without standardization here, you can't identify which sites need help or which inspectors need additional training.
A property inspection company operating across the Southeast learned this lesson painfully. Each site manager had built their own tracking system. Miami tracked completion rates. Atlanta tracked defects per inspection. Nashville tracked customer callbacks. When the operations director tried to identify best practices to replicate across sites, they discovered they couldn't even define what "good" looked like because everyone measured different things.
They rebuilt their data model to capture specific information consistently:
-
Unique inspection ID (year-site-sequence)
-
Property identifier (standardized format)
-
Inspection type (from defined list)
-
Inspector ID + certification level
-
Scheduled vs actual time
-
Finding codes (standardized library)
-
Severity ratings (1-4 scale, clearly defined)
-
Photo requirements (minimum per type)
-
Client communication log
-
Quality review score
The transformation was immediate. They could finally see that Atlanta's lower callback rate wasn't due to better inspections—they were taking 40% longer per inspection. Miami's speed wasn't efficiency—they were missing 30% of standard checkpoint items. Nashville's high satisfaction scores correlated with their photo documentation standards, which became the company-wide requirement.
The phased rollout roadmap
Scaling inspection programs isn't like flipping a switch. Companies that try to transform everything simultaneously usually transform nothing successfully. The ones that build sustainable scale follow a phased approach that validates each component before moving forward.
Phase 1: Standardize the core (Months 1-2)
Start with your highest-volume, most straightforward inspection type. Get one thing working perfectly before touching everything else. Define the exact process, create the templates, build the training materials, establish the quality gates. Run it at one site until it's bulletproof.
Most companies want to skip this phase or rush through it. They'll say their inspections are too varied, their markets too different, their inspectors too experienced to need such rigid structure.
Phase 2: Replicate to second site (Months 3-4)
Take your perfected process to one additional site. Not all sites—one. This reveals every assumption, every undocumented step, every piece of tribal knowledge that didn't make it into the official process.
Phase 3: Technology and automation layer (Months 5-6)
Only after you have a working process across multiple sites should you add technology automation. This seems backwards to most companies who want to start with software, but automation can only improve processes that already work.
Phase 4: Full rollout with continuous optimization (Months 7+)
With validated processes and supporting technology, you can roll out to remaining sites quickly. But "quickly" doesn't mean "carelessly." Each site launch needs a playbook, a trained local champion, and defined success metrics.
Here's a quick visual of the phased rollout workflow.
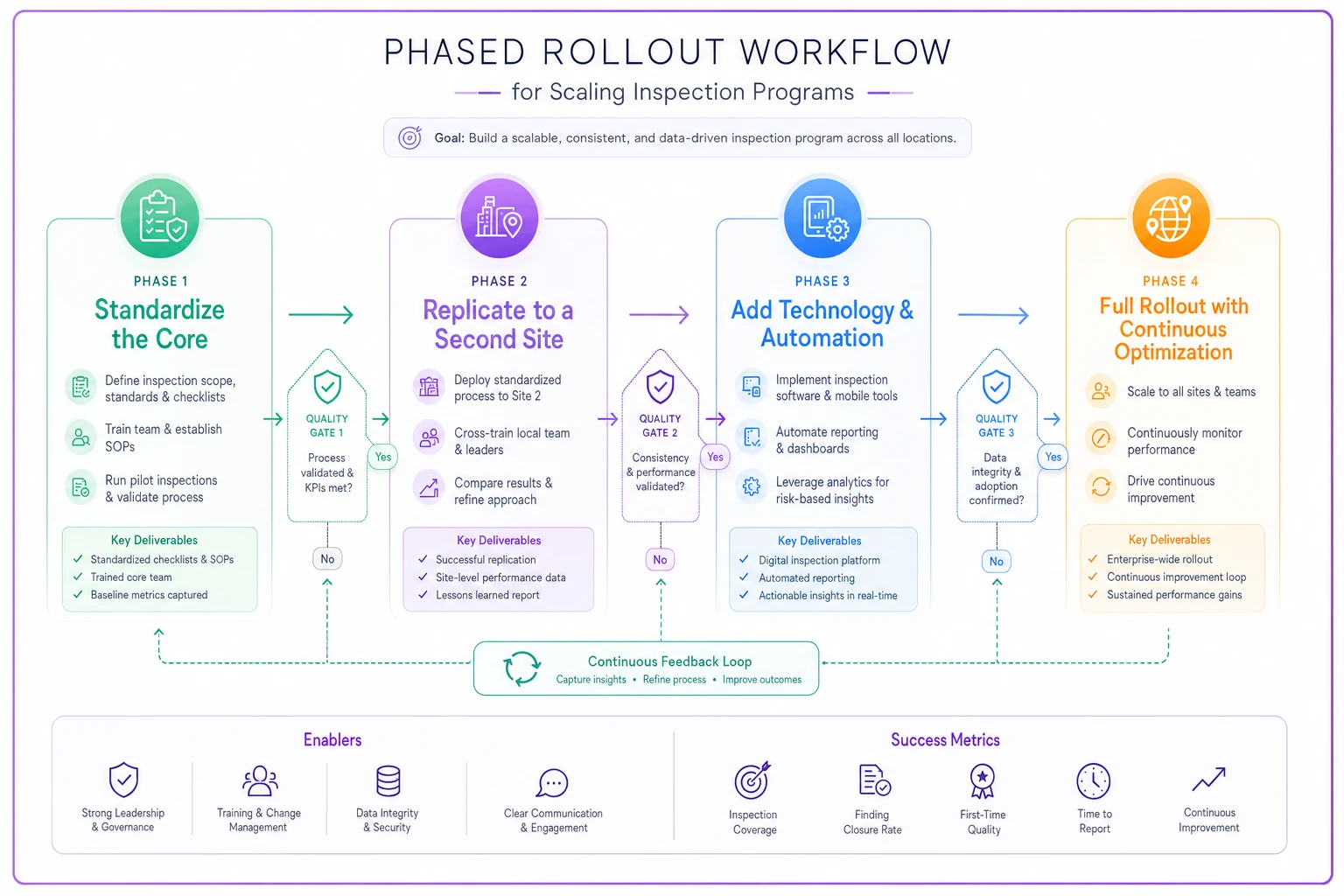
More importantly, you need continuous optimization protocols. Monthly cross-site reviews. Quarterly standard updates. Annual process overhauls. The companies that maintain quality at scale treat their inspection program as a living system, not a fixed solution.
Quality gates that actually work
Quality gates in inspection programs usually fail for one reason: they're designed to catch problems after they happen instead of preventing problems from occurring. The traditional model—supervisor reviews some percentage of completed reports—breaks down at scale because the damage is already done by the time you catch issues.
Effective quality gates work progressively throughout the inspection process. Pre-inspection gates include inspector certification verification, equipment calibration confirmation, previous inspection history review, and client requirement alignment. During-inspection gates involve mandatory photo checkpoints, time-based progression requirements, finding severity validation, and real-time exception flagging. Post-inspection gates focus on automated completeness check, peer review triggers based on complexity, statistical anomaly detection, and client feedback loops.
A commercial property inspection firm implemented this progressive gate system after discovering their end-of-process quality checks were catching issues on 15% of inspections—but those problematic inspections had already consumed full resources and created client friction.
Their new gate system catches most issues before they cascade. Pre-inspection gates prevent unqualified inspectors from starting. During-inspection gates flag unusual patterns immediately—inspection taking 3x normal time, severity ratings all maximum or minimum, photo count below threshold. Post-inspection gates focus on pattern detection across inspectors rather than individual report review.
Result: Quality issues dropped from 15% to 3%, but more importantly, the issues they do catch are now true exceptions rather than process failures.
The human element in scaled operations
The biggest mistake companies make when building scalable inspection programs is designing for efficiency instead of designing for humans. They build perfect processes that assume perfect execution, then wonder why quality varies wildly across sites.
Real scaling accounts for human reality. Experienced inspectors will resist standardized processes because they've "done it their way" for years. New inspectors will follow processes exactly until they gain confidence, then start improvising. Site managers will modify processes to hit their metrics. Field teams will find shortcuts during busy periods.
Instead of fighting human nature, build systems that channel it productively.
Create flexibility within structure. Define the non-negotiables—safety protocols, core data capture, client communication standards—but allow variation in execution sequence, documentation style, and problem-solving approach. An inspector with 20 years experience shouldn't have to follow the same rigid checklist as someone with 20 days experience, but both should achieve the same outcome standards.
Build pride through transparency. Share quality metrics across sites, but focus on improvement trends rather than absolute scores. Celebrate the site that improved their on-time rate from 72% to 88% as much as the site maintaining 95%. Create positive competition through shared learning rather than punitive comparisons.
Invest in continuous development. The companies with sustainable inspection programs treat training as an ongoing process, not a one-time event. Monthly skill workshops. Quarterly standard updates. Annual conferences where field teams share innovations. This investment pays off through reduced turnover and consistent quality improvement.
Common scaling failures and recovery paths
Even well-designed scaling efforts hit predictable failure points. Understanding these patterns helps you recognize problems early and correct course before they become crises.
The complexity cascade happens when you add features and requirements to handle edge cases until the core process becomes so complex that no one follows it correctly. Recovery path: Strip back to essential requirements. Build separate protocols for edge cases rather than complicating the main process. A 20-step inspection process with 80% compliance is worse than a 12-step process with 95% compliance.
The metrics maze occurs when you measure so many things that no one knows what actually matters. Sites optimize for different metrics. Quality becomes whatever makes the numbers look good. Recovery path: Choose 3-5 true north metrics that directly connect to business outcomes. Everything else becomes diagnostic data, not performance measures. One inspection company reduced their dashboard from 47 metrics to 5 and saw immediate improvement in focus and performance.
The technology trap happens when you assume software will solve process problems. Invest heavily in platforms before standardizing operations. End up automating broken processes and making them harder to fix. Recovery path: Freeze technology expansion. Document current state processes. Fix the human workflows first, then gradually reintroduce technology as an enhancer, not a solution.
The tribal knowledge timebomb occurs when critical information lives in senior inspectors' heads. New sites can't replicate success because the "how" was never documented. Quality depends entirely on who's working. Recovery path: Systematic knowledge capture through paired inspections, recorded training sessions, and decision documentation. Transform tribal knowledge into organizational assets before your experienced inspectors retire or leave.
Building your implementation roadmap
Creating a scalable inspection program isn't about perfection—it's about progression. Start where you are, fix the biggest bottleneck, validate the improvement, then tackle the next constraint.
For most inspection operations, the sequence looks like this:
Weeks 1-2: Current state assessment
Map your actual processes, not what you think happens. Track 50 inspections from scheduling through payment. Document every variation, workaround, and informal communication. This baseline becomes your transformation scorecard.
Weeks 3-4: Role architecture design
Define decision rights and interaction patterns for each role. Create escalation paths that don't bottleneck at senior levels. Build coverage models for absences and peak periods.
Weeks 5-8: Core process standardization
Pick your highest-volume inspection type. Build the standard workflow, documentation requirements, and quality thresholds. Test with your best team until it runs smoothly.
Weeks 9-12: Controlled expansion
Roll out to second site with dedicated support. Document every adjustment needed. Refine the core process based on real-world breaks.
Weeks 13-16: Technology enablement
Identify manual steps that software can eliminate or improve. Implement AI-powered scheduling, automated quality checks, intelligent report generation. Focus on tools that reduce variation, not just speed.
Weeks 17-20: Full deployment
Roll out to remaining sites with local champions trained in the standardized process. Establish regular review cycles and continuous improvement protocols.
Ongoing: Optimization and evolution
Monthly cross-site reviews. Quarterly process updates. Annual strategic assessment. The best inspection programs never stop evolving.
Measuring what matters
The inspection companies that successfully scale track different metrics than those that struggle. They measure system health, not just output volume.
Instead of just tracking inspections per day, they monitor inspection time variance—are all sites taking roughly the same time for similar inspections, or is there huge variation suggesting process differences?
Rather than counting completed reports, they track first-pass quality rates—what percentage of inspections require no rework or clarification?
Beyond simple customer satisfaction, they measure inspection-to-resolution time—how quickly do identified issues lead to corrective action?
These system-level metrics reveal whether you're building a scalable inspection program or just pushing more volume through a breaking system.
The path forward
Building a scalable inspection program isn't about finding the perfect process or the ultimate technology solution. It's about creating operational architecture that maintains quality while adapting to growth.
The companies that succeed treat scaling as an engineering challenge, not a management problem. They build systems that assume variation and create consistency through structure, not control. They invest in role clarity before adding headcount, data standardization before analytics tools, and process validation before automation.
Most importantly, they recognize that scaling isn't a project with an end date—it's an ongoing capability that requires constant refinement. The inspection program that works at 50 inspections per week will break at 500. The system that handles 3 sites will need restructuring at 10.
Start with clear role architecture. Build your data model for comparison across sites. Create quality gates that prevent problems rather than just catching them. Roll out changes progressively with validation at each step. And leverage AI-powered operational software not as a silver bullet, but as an amplifier for solid operational foundations.
The difference between inspection programs that scale successfully and those that don't comes down to whether they build systems or just hire more people.
Ready to modernize your inspection process?
Join 500+ inspection teams using Chekzly to reduce paperwork, improve compliance, and accelerate reporting.